In image segmentation, identifying individual objects in a scene becomes significantly more challenging when those objects overlap. Traditional segmentation models typically struggle to separate these entities, often blending multiple instances of the same class into a single prediction. It is where MaskFormer introduces a breakthrough.
Developed with a transformer-based architecture, MaskFormer excels at distinguishing between individual object instances—even when their bounding areas intersect or overlap. This post will explain how MaskFormer tackles overlapping object segmentation, explore its model architecture, and show how to implement it for such tasks.
What Makes Overlapping Object Segmentation Difficult?
Overlapping objects share spatial regions in an image, creating ambiguity in boundaries and visual features. Traditional per-pixel segmentation models predict one label per pixel, which works well for non-intersecting regions but becomes unreliable when multiple instances share visual space.
In such cases:
- Semantic segmentation assigns a class label per pixel (e.g., “car”), but it fails to distinguish between different cars in the same image.
- Instance segmentation is required to separate each object, labeling them as distinct entities (e.g., “car1”, “car2”).
MaskFormer addresses this complexity by integrating mask prediction with class assignment, using transformer-decoded features to predict binary masks for object instances, regardless of how closely or completely they overlap.
MaskFormer’s Architecture
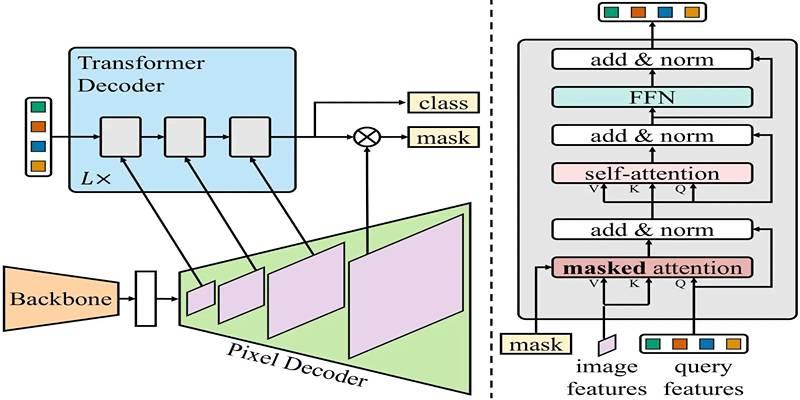
The strength of MaskFormer lies in its mask classification architecture, which treats segmentation as a joint problem of predicting a class label and its associated binary mask. This approach allows the model to segment overlapping objects accurately without relying solely on bounding boxes or pixel-wise labels.
Core Components:
- Backbone Network (CNN): The model begins by passing the input image through a CNN backbone—typically a pre-trained convolutional network like ResNet or Swin Transformer. This backbone extracts rich feature maps, denoted as F, which carry spatial and semantic information about the image.
- Pixel Decoder: Next, the extracted features are fed into a pixel decoder, which converts them into per-pixel embeddings (E). These embeddings capture both the local (fine details) and global (overall structure) context of each pixel.
- Transformer Decoder: In parallel, a transformer decoder processes the image features to generate per-segment embeddings (Q). These embeddings represent the different instances the model aims to identify, assigning weights to various image regions. This two-pronged approach enables MaskFormer to localize and differentiate between object instances—even when they overlap or occlude each other.
- Mask Prediction: To produce the final output, MaskFormer calculates the dot product between pixel embeddings and mask embeddings, followed by a sigmoid activation. This results in a set of binary masks, one for each identified instance. In cases where objects overlap, these binary masks allow the model to still recognize and separate each instance—making it ideal for real-world applications.
- Class Prediction: Each segment is paired with a class label, allowing the model to associate masks with specific object categories.
The model's ability to separate instances is driven by its transformer decoder, which captures long-range dependencies and spatial relationships—crucial for understanding overlapping shapes and textures.
The Role of Binary Masks in Handling Overlaps
One of the standout features of MaskFormer is its use of binary masks to define object instances. Unlike bounding boxes, which offer coarse localization, binary masks provide pixel-level precision, making them ideal for scenarios where objects are closely packed or overlapping.
In MaskFormer, each object instance is represented by a binary mask—a map where each pixel is either marked as belonging to the object (1) or not (0). When multiple objects appear in the same image space, these masks can overlap without conflict since each one is generated independently through the model's transformer-based attention mechanism. This method eliminates ambiguity: even if two objects physically overlap, Mask.
How MaskFormer Handles Overlapping Objects?
What sets MaskFormer apart from earlier models is its mask attention mechanism. Instead of relying on bounding boxes or simple region proposals, it uses learned embeddings to isolate object instances within cluttered or overlapping scenes.
When overlapping objects are detected:
- The transformer decoder generates separate query embeddings for each object.
- These queries selectively attend to different regions of the feature map.
- Even if objects share physical space (e.g., two people standing close), the model can differentiate them using distinct per-segment embeddings.
- Final masks may overlap in the spatial domain, but the model assigns unique labels and binary masks to each instance.
It results in accurate instance segmentation even in tightly packed scenes—achieved through learned spatial representation rather than hard-coded rules or bounding box constraints.
Running the Model
Executing MaskFormer for instance, segmentation is a streamlined process, especially when using pre-trained models. Here's a step-by-step overview of how to perform segmentation on an image with overlapping objects:
Step 1: Importing Required Libraries
Begin by ensuring that the necessary libraries for image processing and segmentation are available in your environment. These typically include modules from the Hugging Face Transformers library, a library for image handling like PIL, and a tool to fetch the image from a web URL.
Step 2: Loading the Pre-trained MaskFormer Model
Next, initialize the feature extractor, which prepares the image (resizing, normalizing, and converting it to tensors). Load the pre-trained MaskFormer model that has been trained on the COCO dataset. This setup enables the model to interpret and process visual data effectively for segmentation.
Step 3: Preparing the Input Image
Select the image you want to segment. In this case, an image is retrieved from a URL and then processed using the feature extractor. This step formats the image correctly so the model can analyze it accurately.
Step 4: Running Inference
Once the image is ready, it's passed through the model to perform inference. The output includes class predictions and corresponding binary masks, which indicate the detected object instances and their locations in the image—even if they overlap.
Step 5: Post-Processing the Output
The raw output from the model is then processed to generate a segmentation map. This map identifies which pixels belong to which object and assigns each pixel a label based on the object class.
Step 6: Visualizing the Segmentation
Finally, the processed results are visualized. Using visualization tools, the segmentation map is displayed, showing how MaskFormer has differentiated and labeled each object in the image, even in regions where the objects overlap.
Conclusion
MaskFormer stands as a significant evolution in the domain of image segmentation. Its ability to handle overlapping objects—a historically difficult challenge—demonstrates the power of combining transformer-based architectures with mask classification. By avoiding traditional per-pixel predictions and instead using a query-based attention mechanism, MaskFormer can separate complex scenes into accurate, distinct object segments—even when those objects share physical space. The model architecture supports both semantic and instance segmentation, but its true strength is in distinguishing object instances without being limited by bounding box overlap or spatial proximity.











