As artificial intelligence continues to scale across industries, one area under constant refinement is information retrieval—the AI’s ability to find and use relevant data in response to complex queries. Traditional models have relied heavily on retrieval-augmented generation (RAG) systems that combine search mechanisms with generative models. While powerful, these systems face limitations when it comes to nuanced understanding, precision, and contextual relevance.
Enter Anthropic’s Contextual RAG, a deceptively simple yet powerfully effective evolution of the standard RAG pipeline. Often described as “stupidly brilliant,” this approach proves that thoughtful, layered optimization of existing techniques can yield dramatic improvements without introducing unnecessary complexity. From hybrid retrieval mechanisms to contextually enriched data chunks and reranking, Contextual RAG redefines how AI can access, understand, and utilize large bodies of information.
What Makes Contextual RAG Magical?
Anthropic’s Contextual RAG builds on the traditional retrieval-augmented generation model with four simple but clever modifications:
1. Embeddings + BM25: Best of Both Worlds
Instead of relying exclusively on semantic embeddings for retrieval, Contextual RAG introduces a hybrid approach by combining them with BM25, a traditional keyword-based retrieval algorithm.
- Embeddings help capture the meaning behind queries and documents.
- BM25 ensures that precise keyword matches aren’t missed.
Why this matters: Embeddings can overlook essential keywords that are syntactically important but semantically vague. By adding BM25 into the mix, the retrieval mechanism becomes both flexible and precise, increasing the chances of fetching exactly what the query requires. This dual strategy gives the system a more balanced understanding—capturing both conceptual and literal relevance.
2. Expanding the Context Window: The Top-20 Chunk Method
Most RAG pipelines only retrieve the top 5 or 10 relevant chunks. But what if the most insightful information is ranked 11th or 15th? Anthropic’s Contextual RAG expands the context window to include the top 20 chunks, thereby giving the model access to a broader base of supporting information.
Why this matters: The wider the retrieval net, the richer the potential response. It doesn’t just improve the quality of answers—it reduces hallucinations and increases confidence in AI-generated insights.
3. Self-Contained Chunks: Context Within the Context
Retrieving 20 chunks is powerful—if each chunk can stand alone. That’s why Contextual RAG enriches each chunk with added contextual information, ensuring that every piece can be interpreted independently. Instead of relying on neighboring data or previous segments, each chunk contains enough surrounding information to be self-contained and immediately useful to the language model.
Why this matters: Without this enhancement, some chunks might appear ambiguous or disconnected. Adding context helps the model understand each chunk in isolation, improving the coherence and completeness of its response.
4. Reranking for Precision and Priority
After retrieval, Contextual RAG applies a reranking step to determine which chunks should be given the most weight. The chunks are sorted based on their relevance to the query, ensuring the most useful content appears first—especially important when dealing with token limits in models.
Why this matters: Models like GPT-4 have token ceilings. Prioritizing content that is most relevant allows the model to focus on the highest-value information, delivering better answers without waste.
Bringing It All Together: The Contextual RAG Workflow
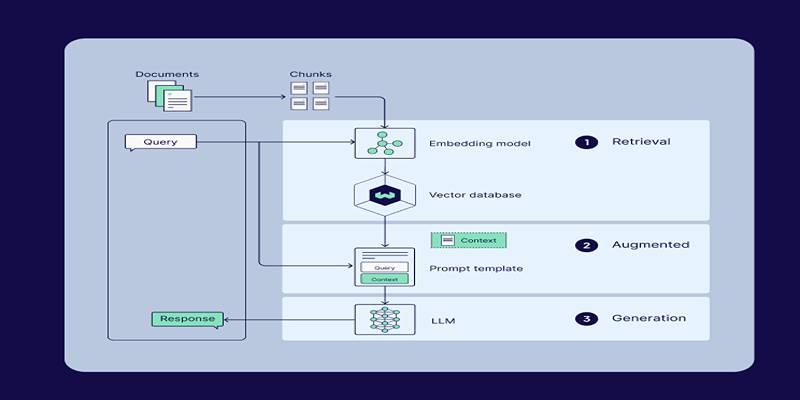
Here’s how these innovations synergize into a fluid and powerful retrieval system:
- A document is split into chunks using a smart text splitter.
- Each chunk is then enriched with its context (based on the surrounding document).
- Two parallel indexes are created:
- One for semantic search (via vector embeddings and FAISS).
- One for keyword-based search (via BM25).
- When a query is submitted, it’s run through both retrieval methods.
- Results are merged and reranked, and only the most relevant, context-rich chunks are passed to the language model.
- The model then generates an answer based on this curated knowledge base.
Hands-On with Contextual RAG: Behind the Magic
Let’s look at what this looks like in practice without going into raw code.
Imagine analyzing Tesla’s Q3 2023 financial report using this pipeline. The document is first split into smaller sections or "chunks." Each chunk is then contextualized—a few lines of summary or additional detail are added to make it understandable even if read on its own. Then, both vector and BM25 indexes are created for these chunks. These indexes allow you to run semantic or keyword-based searches depending on the query.
Now, suppose you ask:
"How does Tesla’s energy business compare to its automotive segment in Q3 2023?"
Rather than searching just keywords or just semantic meaning, Contextual RAG:
- Look for exact matches using BM25.
- Finds thematic matches using vector embeddings.
- Pulls the top 20 most relevant chunks from both.
- Enriches each chunk with the surrounding context.
- Reranks them by relevance to the question.
- Feeds the top-ranked, contextually rich chunks into the model for generation.
The result? An answer that is not only precise but contextually grounded in relevant, multi-faceted data points—something traditional RAGs often miss.
Handling Complex Queries
Where Contextual RAG truly shines is in its handling of multi-part or analytical queries—those that require synthesizing different data points from across a document.
For example:
"How do Tesla’s R&D investments impact their energy and automotive strategies over the next 3–5 years?"
This kind of question requires more than one fact. It demands understanding strategy, financial data, and market context across segments. Contextual RAG’s enriched, reranked chunks give the model the breadth and depth it needs to answer accurately—even when the answer lies in connections, not single sentences.
Simplicity That Wins: Why Contextual RAG Matters

The brilliance of Contextual RAG lies in its elegant simplicity. Each enhancement—embedding + BM25, chunk expansion, self-contained data, reranking—is effective on its own. But when stacked together, they form a powerful system that dramatically improves retrieval and generation.
Here’s what makes it special:
- No new architecture is needed.
- Works with existing language models (like GPT-4).
- Scales easily with larger corpora or document types.
- Reduces hallucinations and boosts factuality.
In a field where innovation often leans toward complexity, Contextual RAG proves that well-designed simplicity can outperform brute force sophistication.
Conclusion
Anthropic’s Contextual RAG isn’t about reinventing the wheel—it’s about refining it to near perfection. By layering proven techniques in thoughtful ways, they’ve built a retrieval system that is faster, smarter, and more reliable than its predecessors. Whether you're analyzing a financial report, researching legal documents, or building enterprise AI assistants, Contextual RAG offers a blueprint for precision-driven retrieval in a world overflowing with data.











